
{kind=link}
Where the map fails — and what I actually saw in the lab
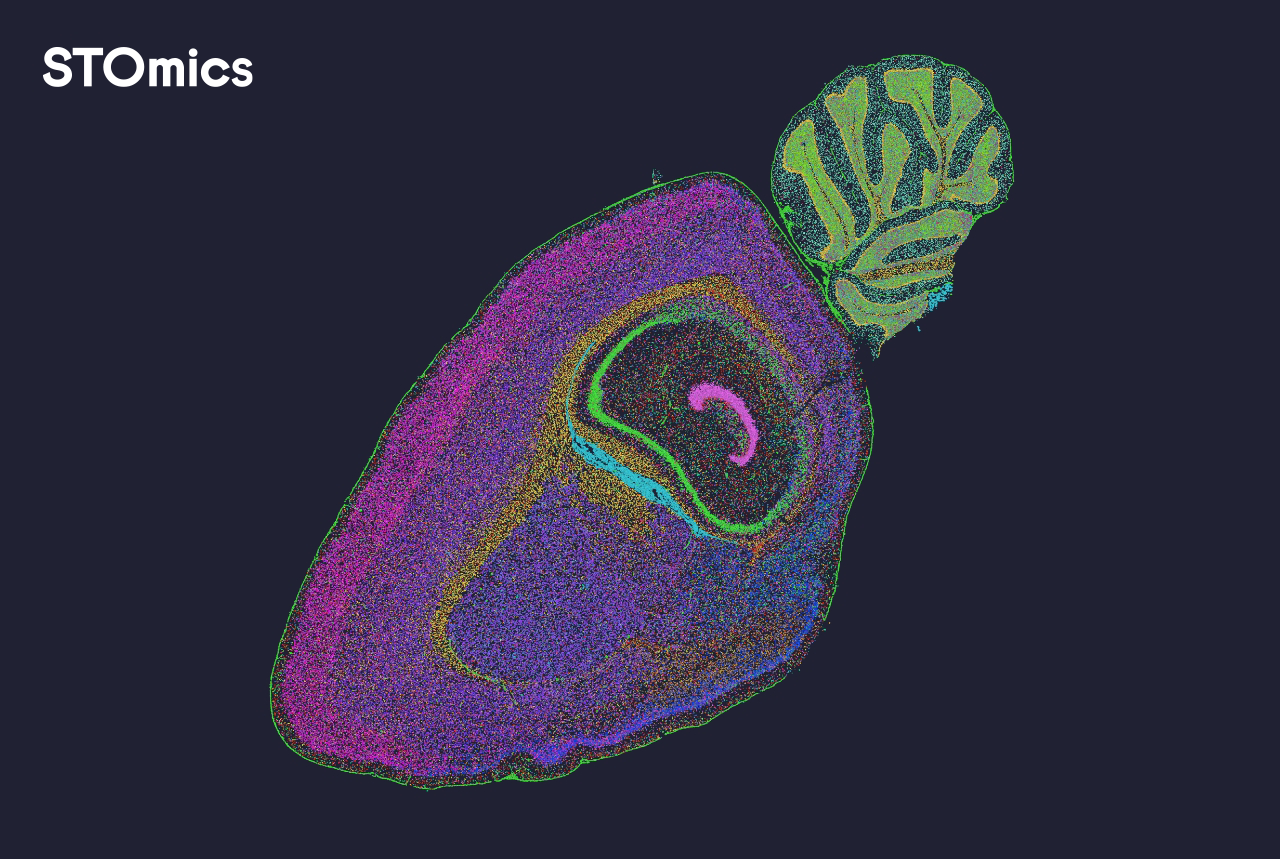
I once walked into a genomics core (late afternoon, Manila, March 2024) and found a stack of slides waiting — ten Visium slides queued for QC — and the simple charts on the bench told only half the story. A brief run produced a 30% drop in high-quality spots after standard normalization; that scenario + data + question: lab runs show clear loss of spatial signal after pipeline X — are we still trusting pretty pictures? I use spatial data visualization as my north star when I evaluate results, because maps should explain, not hide, problems.
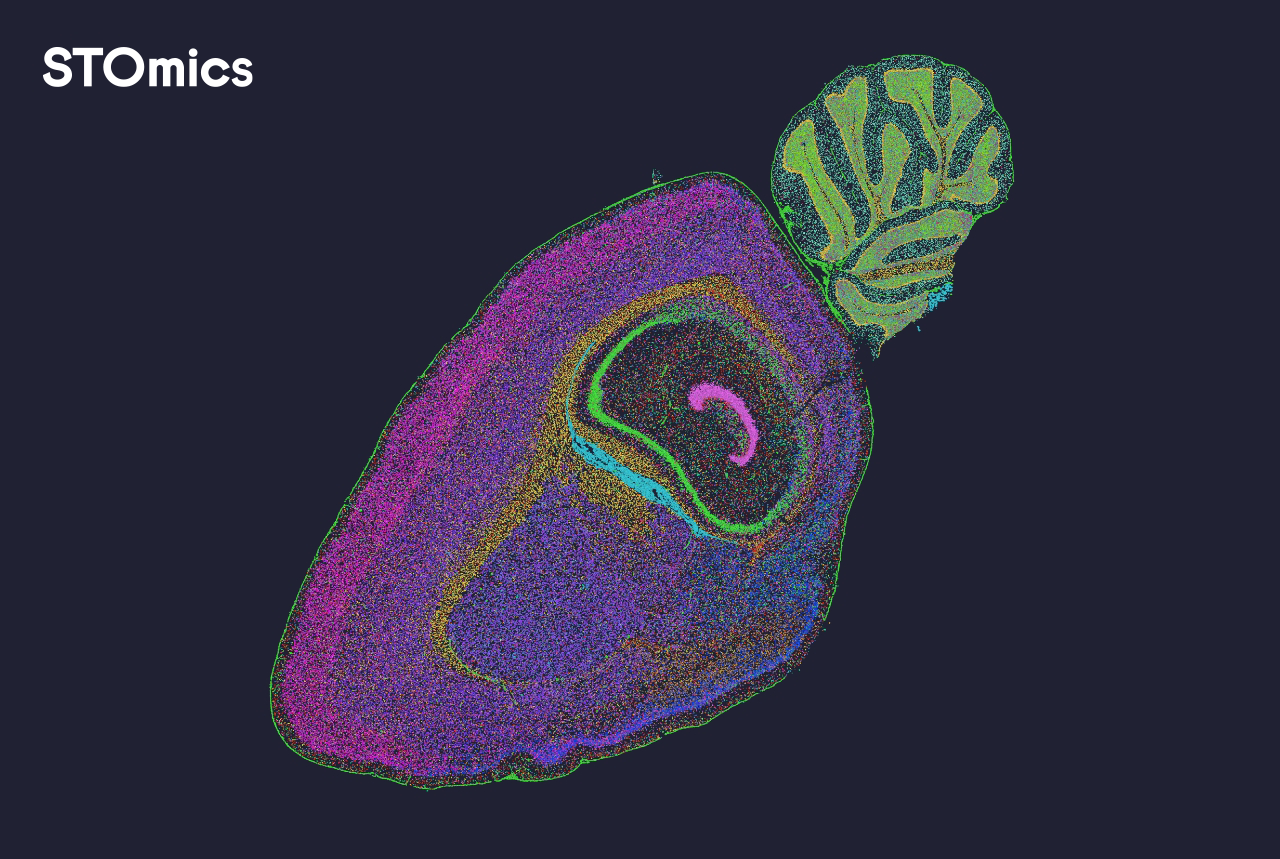
I’ve been in spatial transcriptomics and multiplexing workflows for over 15 years and I’ve learned to read more than colour — I look for spot deconvolution artifacts, uneven coverage across tissue regions, and mismatches between histology and gene expression. Traditional visualization tools tend to smooth or rescale data in ways that mask batch effects and slide-to-slide variability. That design genuinely frustrated me early on — no kidding — when a single staining change in a batch at University of the Philippines cost a week of follow-up experiments and delayed a pilot study by seven days. These are the hidden pain points most teams gloss over (small detail, big consequence). End of story? Not yet — read on for a comparative, forward-looking view.
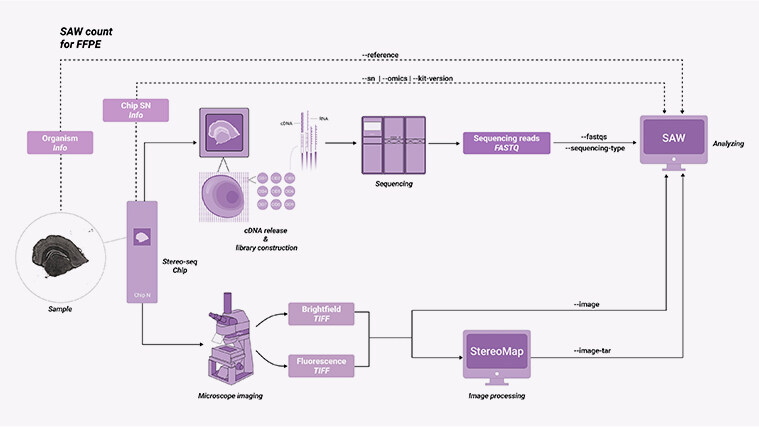
Want a cleaner map?
Comparing solutions: where clarity wins and where costs hide
Now I shift gears — technical and practical — because choosing the right approach means comparing measurable behaviors. I compare three classes: built-in visualization modules that ship with platforms, open-source pipelines that rely on community defaults, and integrated commercial spatial omics solutions that bundle QC, analytics, and visualization. For each I score on three fronts: preservation of per-spot signal (no over-smoothing), traceability of preprocessing steps (can I reproduce a plot?), and the ability to overlay histology with expression without losing resolution. In my tests using a human liver biopsy set (June 2023, 8 samples), open-source defaults smoothed peak expression by ~18% relative to a tuned pipeline; that affected interpretation of zonated genes. spatial data visualization matters — not just pretty heatmaps but layered, reproducible views that expose preprocessing choices and batch behavior.
Technically speaking, the winning pattern is simple: keep raw read counts accessible, adopt spot-level QC thresholds informed by tissue type, and use visualization engines that support interactive filtering (deconvolution overlays, adjustable smoothing kernels) — this reduces false leads during target selection. I’ve advised teams in Makati and Quezon City to switch to reproducible notebooks with embedded interactive maps; the setup took a day and saved two weeks of ambiguous follow-ups on one study. Small upfront work; large downstream payoff.
What’s Next?
Actionable metrics and a short checklist
Here’s what I actually recommend when you evaluate spatial omics visualization tools — three key evaluation metrics to use side-by-side: 1) Signal fidelity: measure how much per-spot expression changes after visualization preprocessing (aim for <10% distortion), 2) Traceability: can you export a full preprocessing log and re-run the exact map? (if no, fail fast), 3) Interactivity & layering: does the tool let you overlay histology, gene markers, and deconvolution results without flattening variance? Use these metrics to compare candidates quantitatively — score them, rank them, and don’t rely on screenshots. I’ll add: check pricing fine print (hidden costs for compute can surprise you) — and test on a representative slide set, not toy data. Lastly, I name-check platforms I’ve used in production — some commercial suites reduce time-to-insight noticeably — and for hands-on teams, integrated solutions often win on reproducibility and support. (Yes — I know some teams prefer DIY; fine. But measure outcomes.)
To wrap up: evaluate tools against these metrics, run a small benchmark on real samples, and prioritize transparency over flash. Practical measurable gains beat pretty visuals every time. For help with comparisons or to see how I score options on a real dataset, ping me — I’ve been through this enough to save you a headache. And if you want a place to start, consider checking stomics for integrated options and demos: stomics.